Architecture:
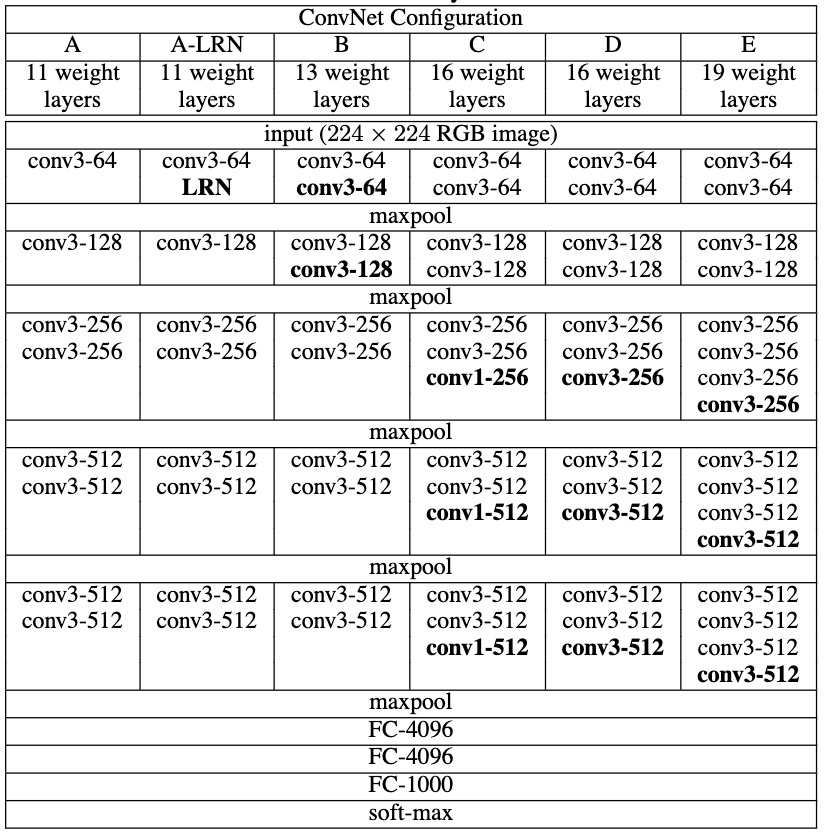
Very Deep Convolutional Networks for Large Scale Image Recognition Paper
Key Libraries and Classes in PyTorch
- torch.nn: This module provides all the building blocks to build neural networks, such as layers loss functions, and activation functions.
- nn.Conv2d: To define convolutional layers.
- nn.MaxPool2d: To define max-pooling layers.
- nn.Linear: To define fully connected layers.
- nn.ReLU: For activation functions.
- nn.Sequential: To stack layers sequentially.
- nn.BatchNorm2d: (Optional) To add batch normalization layers.
- torch.optim: This module includes various optimization algorithms.
- optim.SGD: For stochastic gradient descent optimizer.
- optim.Adam: For Adam optimizer.
- transforms.Compose: To combine multiple transformations.
- torchvision.transforms: This module provides common image transformations.
- transforms.ToTensor: To convert images to PyTorch tensors.
- transforms.Normalize: To normalize image pixel values.
- torchvision.datasets: This module provides easy access to popular datasets.
- datasets.CIFAR10: To load the CIFAR-10 dataset.
- torch.utils.data.DataLoader: This utility helps in creating data loaders to iterate over datasets. DataLoader: To create data loaders for training and validation sets.
from torch.utils.data import DataLoader
from torch import device, backends
from torchvision import transforms, datasets
# import matplotlib.pyplot as plt
# %matplotlib inline
# Using the GPU for pytorch lib (Its called MPS in case of Macbook)
device = device("mps") if backends.mps.is_available() else device("cpu")
devicedevice(type='mps')
# Define transformations for the training and test sets
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
)
data_dir = "./datasets/CIFAR10"
# Download and load the training dataset
trainset = datasets.CIFAR10(
root=data_dir, train=True, download=True, transform=transform
)
train_loader = DataLoader(dataset=trainset, batch_size=32, shuffle=False, num_workers=4)
# trainset.data.shape, trainset.data.dtype
train_loader.dataset.__getitem__(1)[0].shapeFiles already downloaded and verified torch.Size([3, 32, 32])
# Loading test data using the pytorch Lib
testset = datasets.CIFAR10(
root=data_dir, train=False, download=True, transform=transform
)
test_loader = DataLoader(dataset=testset, batch_size=32, shuffle=True, num_workers=4)
testset.data.shape, testset.data.dtype, test_loader.dataset.__getitem__(1)[0].shapeFiles already downloaded and verified ((10000, 32, 32, 3), dtype('uint8'), torch.Size([3, 32, 32]))
## Architecture for VGG-19 ,
# This can be modified to implement other VGG-networks
VGG19 = [
64,
64,
"M",
128,
128,
"M",
256,
256,
256,
256,
"M",
512,
512,
512,
512,
"M",
512,
512,
512,
512,
"M"]import torch.nn as nn
import torch
class VGGNet(nn.Module):
def __init__(self, in_channel=3, num_classes=1000, architecture=VGG19) -> None:
super(VGGNet, self).__init__()
self.in_channel = in_channel
self.num_classes = num_classes
self.conv_layers = self.create_conv_layer(architecture=architecture)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fcl = nn.Sequential(
nn.Linear(512 * 1 * 1, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.conv_layers(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fcl(x)
return x
def create_conv_layer(self, architecture):
layers = []
in_channels = self.in_channel
for x in architecture:
if isinstance(x, int):
out_channels = x
layers += [
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
padding=1,
stride=1,
),
nn.BatchNorm2d(x), # Not in the original paper, but it will improve performance.
nn.ReLU(inplace=True),
]
in_channels = x # for the next layer the in_channels is x
else:
layers += [nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))]
return nn.Sequential(*layers)model = VGGNet(in_channel=3, num_classes=10, architecture=VGG19)
# .to(device=device)
print(model)VGGNet(
(conv_layers): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(25): ReLU(inplace=True)
(26): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(27): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(34): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(35): ReLU(inplace=True)
(36): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(37): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(38): ReLU(inplace=True)
(39): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(44): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(45): ReLU(inplace=True)
(46): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(47): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(48): ReLU(inplace=True)
(49): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(50): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(51): ReLU(inplace=True)
(52): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fcl): Sequential(
(0): Linear(in_features=512, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
standard_input = torch.randn((2, 3, 224, 224))
# .to(device=device)
print(model(standard_input).shape)torch.Size([2, 10])
model(standard_input)tensor([
[-0.1561, 0.3339, 0.0030, -0.0989, 0.2904, 0.0321, 0.3056, 0.0332, 0.1084, -0.0330],
[ 0.1498, 0.1961, 0.1103, 0.0616, 0.0101, -0.2051, 0.1965, 0.0625,-0.0553, 0.0426]], grad_fn=)
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
# .to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
model.train() # Set model to training mode
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# inputs, labels = inputs.to(device), labels.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass and optimize
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.item()
if i % 100 == 99: # Print every 100 mini-batches
print(f"[Epoch {epoch + 1}, Batch {i + 1}] loss: {running_loss / 100:.3f}")
running_loss = 0.0
print("Finished Training")[Epoch 1, Batch 100] loss: 2.392
[Epoch 1, Batch 200] loss: 2.288
[Epoch 1, Batch 300] loss: 2.240
[Epoch 1, Batch 400] loss: 2.149
[Epoch 1, Batch 500] loss: 2.091
[Epoch 1, Batch 600] loss: 2.039
[Epoch 1, Batch 700] loss: 1.980
[Epoch 1, Batch 800] loss: 1.983
[Epoch 1, Batch 900] loss: 1.989
[Epoch 1, Batch 1000] loss: 1.954
[Epoch 1, Batch 1100] loss: 1.979
[Epoch 1, Batch 1200] loss: 1.963
[Epoch 1, Batch 1300] loss: 1.956
[Epoch 1, Batch 1400] loss: 1.956
[Epoch 1, Batch 1500] loss: 1.922
[Epoch 2, Batch 100] loss: 2.008
[Epoch 2, Batch 200] loss: 1.958
[Epoch 2, Batch 300] loss: 1.949
[Epoch 2, Batch 400] loss: 2.000
[Epoch 2, Batch 500] loss: 1.958
[Epoch 2, Batch 600] loss: 1.955
[Epoch 2, Batch 700] loss: 1.882
[Epoch 2, Batch 800] loss: 1.880
[Epoch 2, Batch 900] loss: 1.925
[Epoch 2, Batch 1000] loss: 1.903
[Epoch 2, Batch 1100] loss: 1.993
[Epoch 2, Batch 1200] loss: 1.937
[Epoch 2, Batch 1300] loss: 1.883
[Epoch 2, Batch 1400] loss: 1.872
[Epoch 2, Batch 1500] loss: 1.889
[Epoch 3, Batch 100] loss: 1.895
[Epoch 3, Batch 200] loss: 1.894
[Epoch 3, Batch 300] loss: 1.850
[Epoch 3, Batch 400] loss: 1.887
[Epoch 3, Batch 500] loss: 1.891
[Epoch 3, Batch 600] loss: 1.847
[Epoch 3, Batch 700] loss: 1.800
[Epoch 3, Batch 800] loss: 1.803
[Epoch 3, Batch 900] loss: 1.809
[Epoch 3, Batch 1000] loss: 1.818
[Epoch 3, Batch 1100] loss: 1.795
[Epoch 3, Batch 1200] loss: 1.823
[Epoch 3, Batch 1300] loss: 1.816
[Epoch 3, Batch 1400] loss: 1.781
[Epoch 3, Batch 1500] loss: 1.788
[Epoch 4, Batch 100] loss: 1.788
[Epoch 4, Batch 200] loss: 1.785
[Epoch 4, Batch 300] loss: 1.738
[Epoch 4, Batch 400] loss: 1.726
[Epoch 4, Batch 500] loss: 1.707
[Epoch 4, Batch 600] loss: 1.718
[Epoch 4, Batch 700] loss: 1.661
[Epoch 4, Batch 800] loss: 1.670
[Epoch 4, Batch 900] loss: 1.670
[Epoch 4, Batch 1000] loss: 1.648
[Epoch 4, Batch 1100] loss: 1.651
[Epoch 4, Batch 1200] loss: 1.637
[Epoch 4, Batch 1300] loss: 1.633
[Epoch 4, Batch 1400] loss: 1.626
[Epoch 4, Batch 1500] loss: 1.601
[Epoch 5, Batch 100] loss: 1.632
[Epoch 5, Batch 200] loss: 1.595
[Epoch 5, Batch 300] loss: 1.583
[Epoch 5, Batch 400] loss: 1.570
[Epoch 5, Batch 500] loss: 1.579
[Epoch 5, Batch 600] loss: 1.552
[Epoch 5, Batch 700] loss: 1.517
[Epoch 5, Batch 800] loss: 1.494
[Epoch 5, Batch 900] loss: 1.516
[Epoch 5, Batch 1000] loss: 1.454
[Epoch 5, Batch 1100] loss: 1.505
[Epoch 5, Batch 1200] loss: 1.502
[Epoch 5, Batch 1300] loss: 1.432
[Epoch 5, Batch 1400] loss: 1.422
[Epoch 5, Batch 1500] loss: 1.435
[Epoch 6, Batch 100] loss: 1.470
[Epoch 6, Batch 200] loss: 1.428
[Epoch 6, Batch 300] loss: 1.383
[Epoch 6, Batch 400] loss: 1.370
[Epoch 6, Batch 500] loss: 1.354
[Epoch 6, Batch 600] loss: 1.325
[Epoch 6, Batch 700] loss: 1.343
[Epoch 6, Batch 800] loss: 1.307
[Epoch 6, Batch 900] loss: 1.315
[Epoch 6, Batch 1000] loss: 1.279
[Epoch 6, Batch 1100] loss: 1.290
[Epoch 6, Batch 1200] loss: 1.283
[Epoch 6, Batch 1300] loss: 1.260
[Epoch 6, Batch 1400] loss: 1.245
[Epoch 6, Batch 1500] loss: 1.263
[Epoch 7, Batch 100] loss: 1.226
[Epoch 7, Batch 200] loss: 1.229
[Epoch 7, Batch 300] loss: 1.209
[Epoch 7, Batch 400] loss: 1.211
[Epoch 7, Batch 500] loss: 1.209
[Epoch 7, Batch 600] loss: 1.177
[Epoch 7, Batch 700] loss: 1.210
[Epoch 7, Batch 800] loss: 1.138
[Epoch 7, Batch 900] loss: 1.132
[Epoch 7, Batch 1000] loss: 1.102
[Epoch 7, Batch 1100] loss: 1.150
[Epoch 7, Batch 1200] loss: 1.105
[Epoch 7, Batch 1300] loss: 1.119
[Epoch 7, Batch 1400] loss: 1.107
[Epoch 7, Batch 1500] loss: 1.079
[Epoch 8, Batch 100] loss: 1.046
[Epoch 8, Batch 200] loss: 1.082
[Epoch 8, Batch 300] loss: 1.058
[Epoch 8, Batch 400] loss: 1.038
[Epoch 8, Batch 500] loss: 1.032
[Epoch 8, Batch 600] loss: 1.050
[Epoch 8, Batch 700] loss: 1.040
[Epoch 8, Batch 800] loss: 0.989
[Epoch 8, Batch 900] loss: 1.003
[Epoch 8, Batch 1000] loss: 0.936
[Epoch 8, Batch 1100] loss: 0.980
[Epoch 8, Batch 1200] loss: 0.960
[Epoch 8, Batch 1300] loss: 0.962
[Epoch 8, Batch 1400] loss: 0.928
[Epoch 8, Batch 1500] loss: 0.920
[Epoch 9, Batch 100] loss: 0.899
[Epoch 9, Batch 200] loss: 0.936
[Epoch 9, Batch 300] loss: 0.932
[Epoch 9, Batch 400] loss: 0.914
[Epoch 9, Batch 500] loss: 0.883
[Epoch 9, Batch 600] loss: 0.912
[Epoch 9, Batch 700] loss: 0.892
[Epoch 9, Batch 800] loss: 0.868
[Epoch 9, Batch 900] loss: 0.856
[Epoch 9, Batch 1000] loss: 0.828
[Epoch 9, Batch 1100] loss: 0.881
[Epoch 9, Batch 1200] loss: 0.860
[Epoch 9, Batch 1300] loss: 0.866
[Epoch 9, Batch 1400] loss: 0.821
[Epoch 9, Batch 1500] loss: 0.801
[Epoch 10, Batch 100] loss: 0.770
[Epoch 10, Batch 200] loss: 0.834
[Epoch 10, Batch 300] loss: 0.814
[Epoch 10, Batch 400] loss: 0.814
[Epoch 10, Batch 500] loss: 0.784
[Epoch 10, Batch 600] loss: 0.793
[Epoch 10, Batch 700] loss: 0.784
[Epoch 10, Batch 800] loss: 0.758
[Epoch 10, Batch 900] loss: 0.754
[Epoch 10, Batch 1000] loss: 0.728
[Epoch 10, Batch 1100] loss: 0.773
[Epoch 10, Batch 1200] loss: 0.763
[Epoch 10, Batch 1300] loss: 0.740
[Epoch 10, Batch 1400] loss: 0.708
[Epoch 10, Batch 1500] loss: 0.706
Finished Training
# Performing Test on the test data
def test_model(model, test_loader, criterion, device="cpu"):
model.eval() # Set the model to evaluation mode
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # Disable gradient computation
for inputs, targets in test_loader:
# inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item() * inputs.size(0) # Accumulate test loss
_, predicted = torch.max(outputs, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
avg_test_loss = test_loss / total
accuracy = 100 * correct / total
print(f"Test Loss: {avg_test_loss:.4f}, Test Accuracy: {accuracy:.2f}%")
return avg_test_loss, accuracy
test_loss, test_accuracy = test_model(model, test_loader, criterion)Test Loss: 0.7965, Test Accuracy: 73.12%