This is a way for me to follow all the best practises from the pytorch team and learn them rather than learning from some website on the internet that havent been updated for a while. More hands one experience right from the basics. I believe Andrej Karpathy has build a RNNS model on a character level in 2023 using mostly numpy. It is a great resource to start. Link to the basic lessons: Read More Here
RNNs
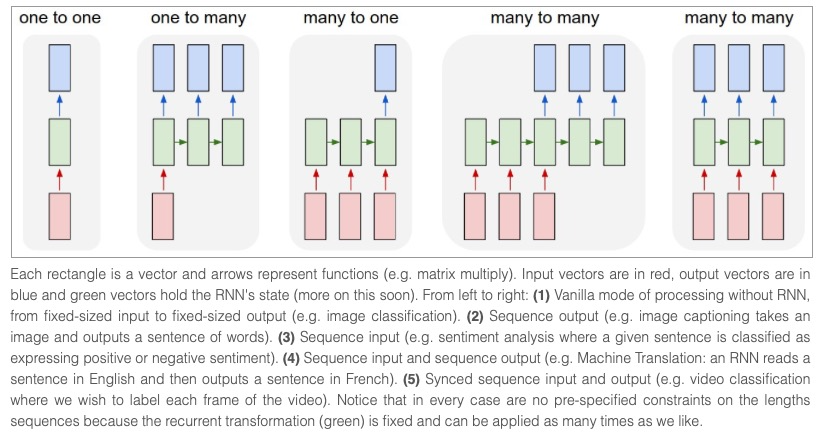
image source: CS231n
One big problem with CNNs is that the input and outputs are fixed. This limits the CNNs from being dynamic and due to its rigidity hinders it from being a intelligent system.
RNNs combines the input vector with their state vector with a learned fixed function to produce a new state vector.
In fact, it is known that RNNs are Turing-Complete in the sense that they can to simulate arbitrary programs (with proper weights)[1].
This blog by Karpathy is a great resoure on effectiveness RNNs: The Unreasonable Effectiveness of Recurrent Neural Networks. Also checkout the explanation on RNNs from CS231 course from Stanford University.
The LSTM, a specialized type of recurrent neural network (RNN), generally performs better in practice due to its more advanced update mechanism and advantageous backpropagation dynamics. While the underlying principles of RNNs remain unchanged, the equation for updating the hidden state becomes more complex with LSTMs. In this context, although I may refer to RNNs and LSTMs interchangeably, the experiments discussed here are specifically conducted with LSTMs.
from io import open
import random
import glob
import os
import unicodedata
import string
from dotenv import load_dotenv
import sys
import torch
load_dotenv() # do not remove from here. do the imports all togetger
True
Preface work
We are getting the locations of all the names in the datastet that will be later used to read these files and extract the data from them.
Also we will make sure that we are using CPU or GPU (if available)
def getDeviceInfo():
_platform = sys.platform # Check platform
gpu = ''
if _platform == "darwin" and torch.backends.mps.is_available():
gpu = 'mps'
elif torch.cuda.is_available():
gpu = 'cuda'
else:
gpu = 'cpu'
return gpu
device = torch.device(getDeviceInfo())
print(f"Using device: {device}")Using device: mps
dataset = os.getenv("NLP1_DATASET_PATH")
def findFiles(path):
return glob.glob(path)The next job is to prepare the dataset. The data/names directory contains 18 text files, each named after a specific language, following the format [Language].txt. Each file lists one name per line, primarily in romanized form, though Unicode to ASCII conversion is still necessary.
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
# turning a unicode string to ASCII
def unicodeToAscii(s):
return "".join(
c
for c in unicodedata.normalize("NFD", s)
if unicodedata.category(c) != "Mn" and c in all_letters
)
unicodeToAscii("Ślusàrski")'Slusarski'
Preparing the dataset
Ultimately, the goal is to create a dictionary where each language is associated with a list of names, structured as {language: [names...]}. The general terms "category" and "line" are used to represent "language" and "name" respectively, allowing for easier future adaptation.
all_cat = []
cat_lines = {}
def readlines(filepath : string):
lines = open(filepath, "r", encoding='utf-8').read().strip().split()
return [unicodeToAscii(line) for line in lines]
for filename in findFiles(dataset):
category = os.path.splitext(os.path.basename(filename))[0]
all_cat.append(category)
lines = readlines(filename)
cat_lines[category] = lines
num_cat = len(all_cat)
Representing this data into tensors
Data can be easily represented using tensors using the one_hot encoding
import torch
v_to_i = {v: i for i, v in enumerate([letter for letter in all_letters])}
def lineToTensor(line: string) -> torch.tensor:
t = [[v_to_i[l] for l in w] for w in line]
tens = torch.zeros(
len(t), 1, n_letters
) # Make a zeros tensor with dimen [input length,1,vocab size]
for i, val in enumerate(t):
tens[i][0][val] = 1
return tens
# lineToTensor("hello, hi"), lineToTensor("J"), lineToTensor("Jones")
v_to_i{'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4, 'f': 5, 'g': 6, 'h': 7, 'i': 8, 'j': 9, 'k': 10, 'l': 11, 'm': 12, 'n': 13, 'o': 14, 'p': 15, 'q': 16, 'r': 17, 's': 18, 't': 19, 'u': 20, 'v': 21, 'w': 22, 'x': 23, 'y': 24, 'z': 25, 'A': 26, 'B': 27, 'C': 28, 'D': 29, 'E': 30, 'F': 31, 'G': 32, 'H': 33, 'I': 34, 'J': 35, 'K': 36, 'L': 37, 'M': 38, 'N': 39, 'O': 40, 'P': 41, 'Q': 42, 'R': 43, 'S': 44, 'T': 45, 'U': 46, 'V': 47, 'W': 48, 'X': 49, 'Y': 50, 'Z': 51, ' ': 52, '.': 53, ',': 54, ';': 55, "'": 56}
Testing code
Basic testing before moving forward. This needs to be consistent to check my output.
## Did some testing to verify the learning code functions and my code returns the same results
# Tutorial version
def tutorial_lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# Test function
def compare_outputs(input_line):
out = lineToTensor(input_line)
tutorial_output = tutorial_lineToTensor(input_line)
print(f"Input: {input_line}")
shape_match = out.shape == tutorial_output.shape
val_match = torch.all(out == tutorial_output)
assert val_match
print(f"Shapes match: {shape_match}:{out.shape} \nValues match: {val_match}")
if not val_match:
print("Differences:")
print(torch.where(out != tutorial_output))
# Test with sample inputs
test_inputs = [
"hello",
"WORLD",
"NLP",
"PyTorch",
"Machine Learning",
"A.I.",
"Natural Language Processing",
"\'.,;", # Note: These special characters might not be in all_letters
"Hello, World",
"Test case; with punctuation.",
"Mixed Case and Nums",
"EmptySpaces Test",
"a", # Single character test
"", # Empty string test
"'.;,\',;.", # Only punctuation
"aA.,;'zZ", # Mix of everything
]
for input_line in test_inputs:
compare_outputs(input_line)
print()
Input: hello Shapes match: True:torch.Size([5, 1, 57]) Values match: True
Input: WORLD Shapes match: True:torch.Size([5, 1, 57]) Values match: True
Input: NLP Shapes match: True:torch.Size([3, 1, 57]) Values match: True
Input: PyTorch Shapes match: True:torch.Size([7, 1, 57]) Values match: True
Input: Machine Learning Shapes match: True:torch.Size([16, 1, 57]) Values match: True
Input: A.I. Shapes match: True:torch.Size([4, 1, 57]) Values match: True
Input: Natural Language Processing Shapes match: True:torch.Size([27, 1, 57]) Values match: True
Input: '.,; Shapes match: True:torch.Size([4, 1, 57]) Values match: True
Input: Hello, World Shapes match: True:torch.Size([12, 1, 57]) Values match: True
Input: Test case; with punctuation. Shapes match: True:torch.Size([28, 1, 57]) Values match: True
Input: Mixed Case and Nums Shapes match: True:torch.Size([19, 1, 57]) Values match: True
Input: EmptySpaces Test Shapes match: True:torch.Size([18, 1, 57]) Values match: True
Input: a Shapes match: True:torch.Size([1, 1, 57]) Values match: True
Input: Shapes match: True:torch.Size([0, 1, 57]) Values match: True
Input: '.;,',;. Shapes match: True:torch.Size([8, 1, 57]) Values match: True
Input: aA.,;'zZ Shapes match: True:torch.Size([8, 1, 57]) Values match: True
Creating a Vanilla RNN using pytorch
import torch.nn as nn
import torch.nn.functional as F
class RNN(nn.Module):
def __init__(self, input_size : int , hidden_size : int , output_size : int):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.l1 = nn.Linear(input_size, hidden_size)
self.l2 = nn.Linear(hidden_size, hidden_size)
self.l3 = nn.Linear(hidden_size, output_size)
# self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
hidden = F.tanh(self.l1(input) + self.l2(hidden)) # adding lin(hidden size) + lin(hidden size)
output = self.l3(hidden)
# output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)n_hidden = 128 # Some arbitary number for now
model = RNN(n_letters, n_hidden, num_cat).to(device)
print(model)RNN(
(l1): Linear(in_features=57, out_features=128, bias=True)
(l2): Linear(in_features=128, out_features=128, bias=True)
(l3): Linear(in_features=128, out_features=18, bias=True)
(softmax): LogSoftmax(dim=1)
)
from torchinfo import summary
# Define input and hidden tensors for the summary
input_tensor = torch.zeros(1, n_letters)
hidden_tensor = model.initHidden()
# Print model summary using torchinfo
summary(RNN(n_letters, n_hidden, num_cat), input_data=[input_tensor, hidden_tensor], col_names=["input_size", "output_size", "num_params", "mult_adds"])============================================================================================================================================
Layer (type:depth-idx) Input Shape Output Shape Param # Mult-Adds
============================================================================================================================================
RNN [1, 57] [1, 18] -- --
├─Linear: 1-1 [1, 57] [1, 128] 7,424 7,424
├─Linear: 1-2 [1, 128] [1, 128] 16,512 16,512
├─Linear: 1-3 [1, 128] [1, 18] 2,322 2,322
├─LogSoftmax: 1-4 [1, 18] [1, 18] -- --
============================================================================================================================================
Total params: 26,258
Trainable params: 26,258
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 0.03
============================================================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.11
Estimated Total Size (MB): 0.11
============================================================================================================================================input = lineToTensor("Albert")
hidden = torch.zeros(1, n_hidden) # make a 1, 128 array
output, next_hidden = model(input, hidden)
print(output.shape, next_hidden.shape)torch.Size([6, 1, 18]) torch.Size([6, 1, 128])
def categoryFromOutput(output):
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_cat[category_i], category_i
print(categoryFromOutput(output))('Czech', 0)
Getting Random training example
The goal here to the get a random language(class) from the dataset. Then pick a random line from the that language's dataset. Get the category number and make a tensor for the line read from the dataset.
randomChoice = lambda l: l[random.randint(0, len(l) - 1)]
def randomTrainingExample():
category = randomChoice(all_cat) # get a random category
line = randomChoice(cat_lines[category])
category_tens = torch.tensor([all_cat.index(category)], dtype= torch.long)
line_tensor = lineToTensor(line)
return category , line , category_tens , line_tensor
for i in range(10):
category, line, category_tensor, line_tensor = randomTrainingExample()
print('category =', category, '/ line =', line)
category = English / line = Neale
category = Russian / line = Juhimuk
category = Greek / line = Polymenakou
category = Scottish / line = Christie
category = Vietnamese / line = Duong
category = Spanish / line = Rojas
category = Chinese / line = Chi
category = Italian / line = Pesce
category = Irish / line = Macshuibhne
category = French / line = Cousineau\
Training the Model!
Now we can start training the model to do classification task for names.
To train the mode, we will need :
- A criterion. We are using
nn.CrossEntropyLossas our choice of criterion. It is a loss function that measures how well your model's predictions match the actual target values.
Each Loop of the training will consist :
- Creating an input and target data
- Creating a
torch.zerosinitial hidden state - Read each letter in and keep hidden state for the next letter
- Compare the final output to target using the Cross Entropy Loss
- Back Prop
- Return the output and results
- Rinse and Repeat
criterion = nn.CrossEntropyLoss().to(device)lr= 5e-3
def train(category_tensor, line_tensor):
hidden = model.initHidden()
model.zero_grad()
for i in range(line_tensor.size()[0]):
output, hidden = model(line_tensor[i] , hidden)
loss = criterion(output, category_tensor)
loss.backward()
for p in model.parameters():
p.data.add_(p.grad.data, alpha=-lr)
return output, loss.item()
# train()import time
import math
n_iters = 100000
print_every = 5000
plot_every = 1000
# Keep track of losses for plotting
current_loss = 0
all_losses = []
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
start = time.time()
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
# Print ``iter`` number, loss, name and guess
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else '✗ (%s)' % category
print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# Add current loss avg to list of losses
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 05000 5% (0m 2s) 1.0455 Dagher / Arabic ✓
10000 10% (0m 5s) 0.0624 Pantelakos / Greek ✓
15000 15% (0m 7s) 1.3450 Breitbarth / German ✓
20000 20% (0m 10s) 1.1973 Luo / Vietnamese ✗ (Chinese)
25000 25% (0m 12s) 5.3349 Comino / Portuguese ✗ (Greek)
30000 30% (0m 15s) 0.7361 Marek / Polish ✓
35000 35% (0m 17s) 1.2471 Chong / Chinese ✗ (Korean)
40000 40% (0m 20s) 1.7424 Siena / Spanish ✗ (Italian)
45000 45% (0m 22s) 1.5558 Brant / Scottish ✗ (German)
50000 50% (0m 25s) 0.5561 Vega / Spanish ✓
55000 55% (0m 27s) 0.2479 Guadarrama / Spanish ✓
60000 60% (0m 30s) 4.7581 Donohoe / Greek ✗ (English)
65000 65% (0m 32s) 0.0341 Esimontovsky / Russian ✓
70000 70% (0m 35s) 0.2816 Teague / Irish ✓
75000 75% (0m 37s) 0.0618 Russell / Scottish ✓
80000 80% (0m 40s) 0.7942 Chu / Vietnamese ✗ (Korean)
85000 85% (0m 42s) 0.6592 Trujillo / Spanish ✓
90000 90% (0m 45s) 0.0065 Ruadhain / Irish ✓
95000 95% (0m 48s) 0.0178 Aitken / Scottish ✓
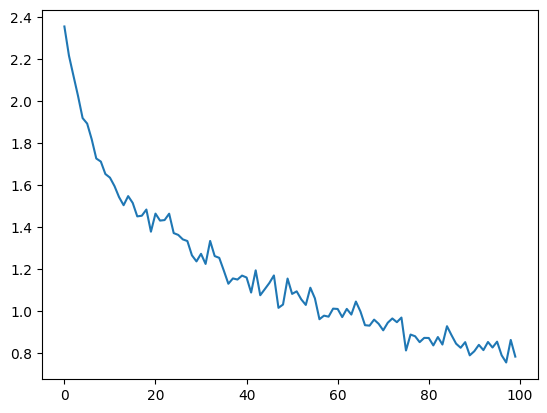
100000 100% (0m 50s) 1.9986 Brady / Irish ✗ (English)import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)[<matplotlib.lines.Line2D at 0x15889cc50>]
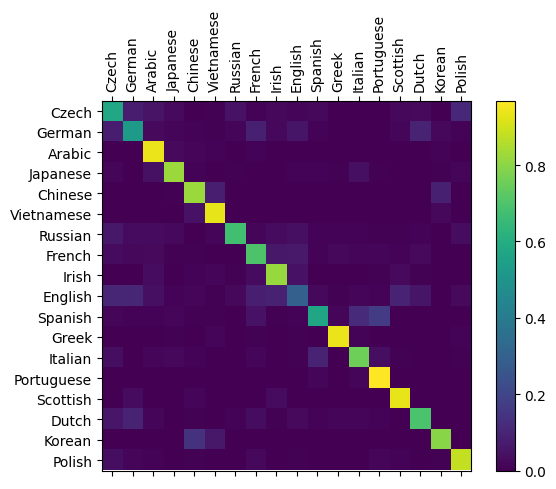
# Keep track of correct guesses in a confusion matrix
confusion = torch.zeros(num_cat, num_cat)
n_confusion = 10000
# Just return an output given a line
def evaluate(line_tensor):
hidden = model.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = model(line_tensor[i], hidden)
return output
# Go through a bunch of examples and record which are correctly guessed
for i in range(n_confusion):
category, line, category_tensor, line_tensor = randomTrainingExample()
output = evaluate(line_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_cat.index(category)
confusion[category_i][guess_i] += 1
# Normalize by dividing every row by its sum
for i in range(num_cat):
confusion[i] = confusion[i] / confusion[i].sum()
# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + all_cat, rotation=90)
ax.set_yticklabels([''] + all_cat)
# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()/var/folders/3n/4576xhhx407g460wd3kvw8000000gn/T/ipykernel_88620/712728530.py:33: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels([''] + all_cat, rotation=90)
/var/folders/3n/4576xhhx407g460wd3kvw8000000gn/T/ipykernel_88620/712728530.py:34: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_yticklabels([''] + all_cat)\
def predict(input_line, n_predictions=3):
print('\n> %s' % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
# Get top N categories
topv, topi = output.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print('(%.2f) %s' % (value, all_cat[category_index]))
predictions.append([value, all_cat[category_index]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')> Dovesky
(-0.26) Czech
(-1.82) Russian
(-3.25) English
> Jackson
(-0.06) Scottish
(-3.47) English
(-4.09) Polish
> Satoshh
(-1.02) Arabic
(-1.50) Portuguese
(-1.59) Polish
References
- [1] A. Karpathy, “The Unreasonable Effectiveness of Recurrent Neural Networks,” karpathy.github.io, May 21, 2015. https://karpathy.github.io/2015/05/21/rnn-effectiveness/